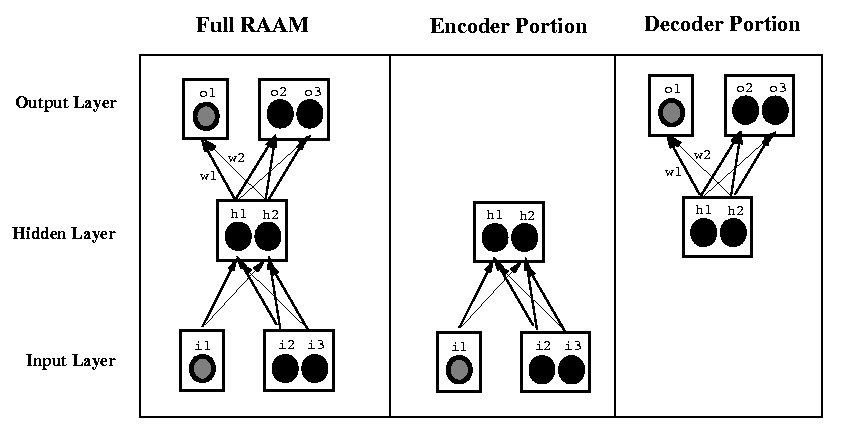
Recursive Auto-Associative Memory (RAAM)
-
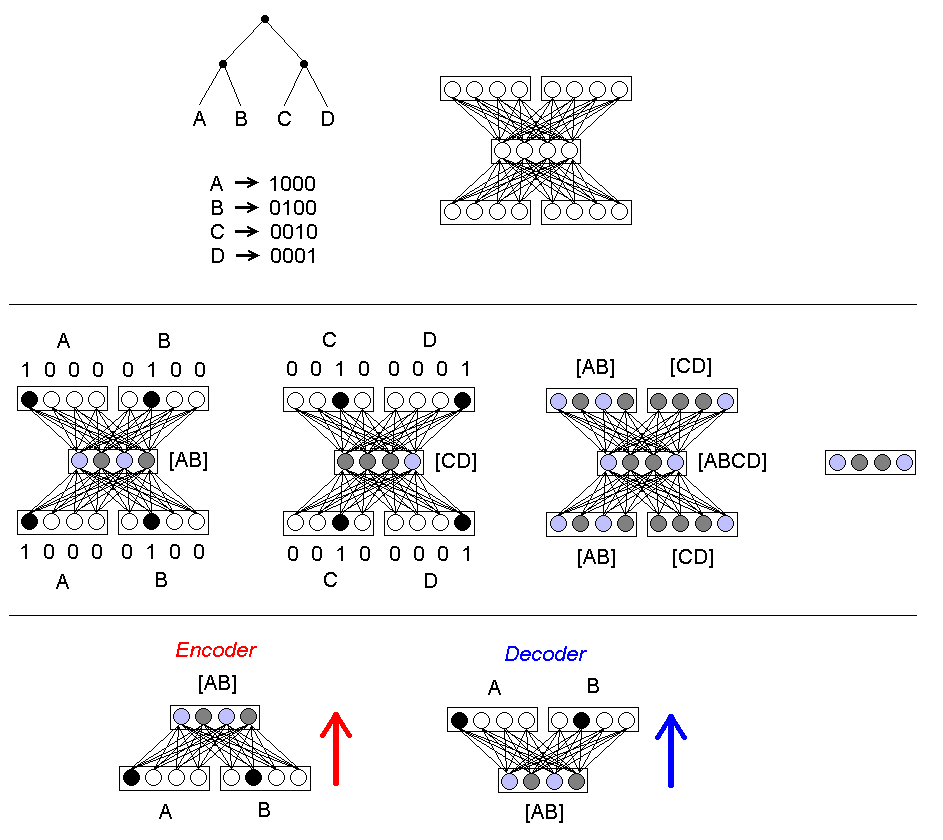
Technique for encoding recursive data structures (lists and
trees) as distributed numerical vectors
-
Example: [0.34, -0.93, -0.02, 0.78, 0.53]
-
Developed by Jordan Pollack
-
Uses feedforward network architecture, backpropagation to
encode arbitrary-depth trees with fixed branching factor k into
distributed representations of length n
-
Network trained by auto-association
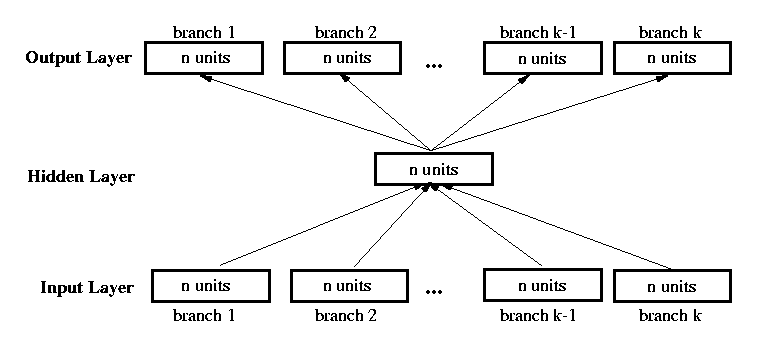
Training a RAAM Network
Sequential RAAM
-
Special case: sequences of symbols
-
Equivalent to a right-branching binary tree
-
Hidden layer may contain any number of units
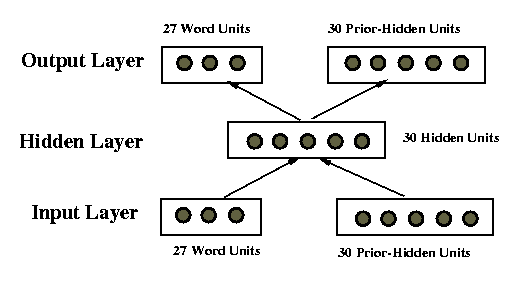
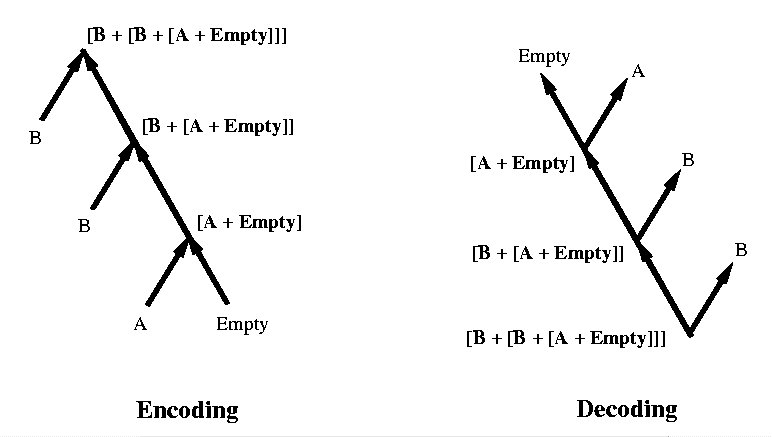
Example: Sequence ABB
A Case Study of RAAM
-
Joint work with Doug Blank and Lisa Meeden
-
Analyzed behavior of a sequential 3-2-3 RAAM
-
Used larger RAAM to encode simple sentences
-
Analyzed resulting distributed representations of words and
sentences
-
Examined ability to perform computations with distributed
representations
- Trained 3-2-3 RAAM on eight sequences of symbols A and B
- AAA
- BAA
- ABB
- BBB
- AAB
- BBA
- ABA
- BAB
- RAAM produced decoding errors on first element of sequences 4 and 8
- Errors due to restricted size of hidden layer
- Plot of hidden representation space:
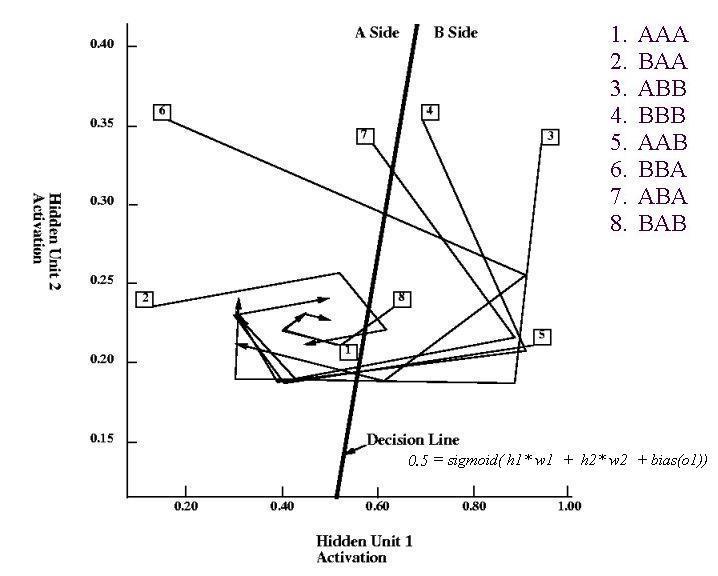
- All points to left of decision line have A as the next element
- Sequences with h2 < 0.30 have middle element A
- End-marker represented by [0.25, 0.25] (other choices yield poorer
performance with 3-2-3 RAAM, but not with 4-3-4 RAAM)
- Generalization test:
Sentence Generation
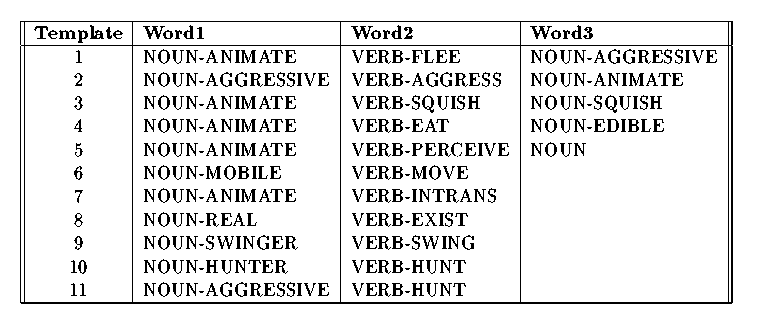
Simple grammar generated 2- and 3-word
sentences using 26 words (15 nouns, 11 verbs) + end-marker (similar to Elman, 1990):

Templates used by the sentence generator:
Example sentences:

-
Grammar highly constrains set of valid sentences
-
18,252 possible sequences
Network Architecture
27-bit localist representation of words
-
100000000000000000000000000 = tarzan
-
010000000000000000000000000 = jane
-
001000000000000000000000000 = boy
-
. . . etc. . . .
-
000000000000000000000000001 = end-marker
Sequential RAAM with 30 hidden units
We don't want
to commit to a particular structuring of the input (e.g., a parse
tree). Want the network to discover good representations of sentences
on its own.
TRAINING set: 100 random sentences
TESTING set: 100 different sentences
Network Performance
100 TRAINING sentences presented in random order for
~ 21,000 epochs
Test 1: Encoding and decoding
-
Encode a sentence and then decode it to see if resulting
sentence is the same.
-
Error: correct unit < 0.5 or another
unit > correct unit
-
100% of TRAINING sentences passed, 80% of TESTING sentences
-
15/20 errors had correct unit < 0.5 for at least one word
in sentence (more training would probably fix this).
-
5/20 errors had incorrect word. Most of these errors
were due to low word frequencies in training corpus.
-
Incorrect words were usually still of the same grammatical
type (e.g., jane instead of jeep)
Test 2: Ungrammatical sentences
-
Encode and then decode 20 ungrammatical sentences.
Examples:
-
tarzan chase bigfoot (tarzan not NOUN-AGGRESSIVE)
-
bigfoot exist (bigfoot not NOUN-REAL)
-
berries chase meat (berries not NOUN-AGGRESSIVE,
meat
not NOUN-ANIMATE)
-
eat tree eat (sentence not of the form NOUN
VERB NOUN)
-
Only 35% were correctly decoded
-
86% of the correctly decoded sentences were only slightly
ungrammatical
-
Difficulty encoding/decoding ungrammatical sentences
Analysis of Encoded Sentences
Performed cluster analysis of 100 encoded TRAINING
sentences
30-dimensional space --> tree structure
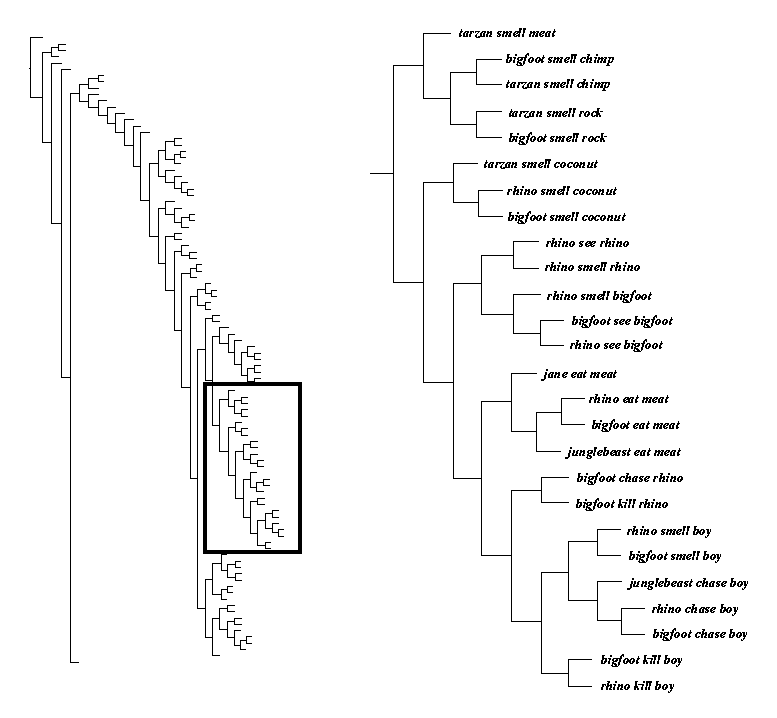
Observations:
-
sentences of last cluster all end in boy
-
clustering not based simply on last word of sentence
-
middle cluster: aggressive nouns perceiving aggressive
nouns
-
smelling of meat separated from eating of meat
-
sentences with berries or banana clustered
together, far away from sentences with coconut or meat (i.e.,
squishable edibles distinguished from non-squishable edibles)
-
sentences ending with eat meat or smell coconut
are clustered based on aggressive or non-aggressive first word
Composite Word Representations
An encoded word representation was created for each
of the 286 words appearing in the original 100 TRAINING sentences.
Example:
tarzan eat banana
[] tarzan
H1
[tarzan] eat
H2
[[tarzan] eat] banana
H3
jane see tarzan
[] jane
H4
[jane] see
H5
[[jane] see] tarzan
H6
tarzan = average( H1, H6, . . . )

Observations:
-
6th hidden unit encodes noun/verb distinction (except for
jeep, which was underrepresented in the TRAINING corpus)
-
This word feature has been learned by the network
Cluster analysis of composite word representations:
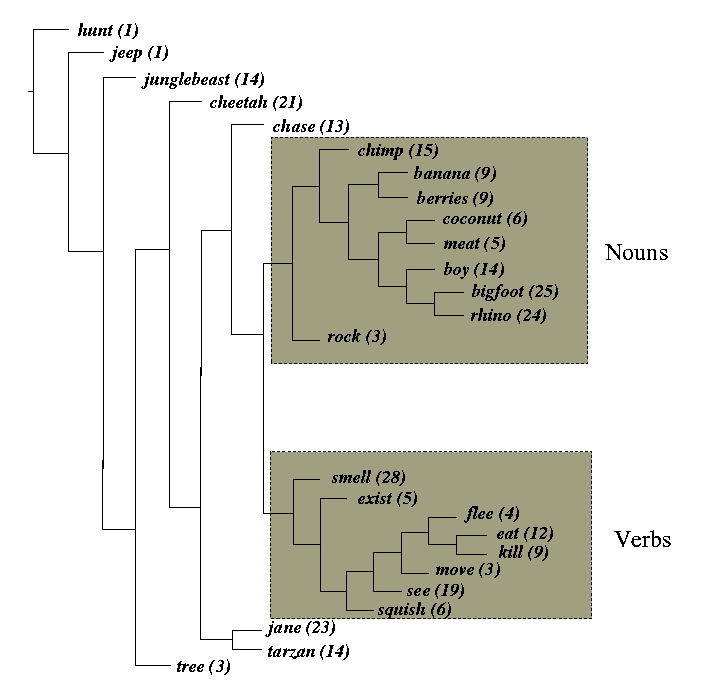
Observations:
-
Good but not perfect separation of nouns and verbs
-
Probably due to small size of TRAINING corpus
-
Training on 300 instead of 100 sentences reduces number of exceptions to 5
-
Elman's study used 10,000 sentences and had complete noun/verb
separation
-
Squishable/non-squishable foods clustered together
-
Within main noun cluster, aggressive nouns clustered together
(bigfoot, rhino)
-
Structure of grammar reflected in distributed representations,
even though no explicit information about the grammar was provided to the
network.
Holistic Operations on Distributed Representations
Can useful information be extracted directly from
distributed representations, without first decoding them into their constituent
parts?
Experiments involving three types of operations were performed
-
Feature detection
-
Parallel decoding
-
Syntactic transformations
Feature Detection
Can particular features of distributed representations
be recognized?
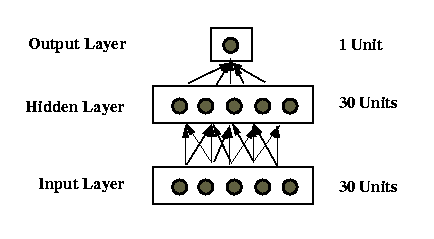
1. Aggressive-animal detector
-
tarzan eat banana --> NO
-
junglebeast kill chimp --> YES
-
bigfoot smell banana --> YES
-
Trained on 50 TRAINING sentences for ~ 300 trials
-
Performance on other 50 TRAINING sentences: 88% correct
-
Performance on 100 TESTING sentences (double-generalization): 85% correct
2. Aggressive-animal and human detector
-
junglebeast kill chimp --> NO
-
junglebeast kill boy --> YES
-
Category "human" (i.e., tarzan, jane, boy)
was not part of grammar
-
Trained on 50 TRAINING sentences
-
Performance on other 50 TRAINING sentences: 84% correct
-
Performance on 100 TESTING sentences (double-generalization): 85% correct
3. Reflexive sentence detector
-
bigfoot smell bigfoot
-
jane see jane
-
Used new training corpus (28 reflexive sentences, 40 non-reflexive)
-
Hidden layer decreased to 15 units
-
Network was unable to learn to detect this type of sentence
Parallel Decoding
Is the sequential peeling-off of one symbol at a time
the only method for retrieving information from a distributed representation?
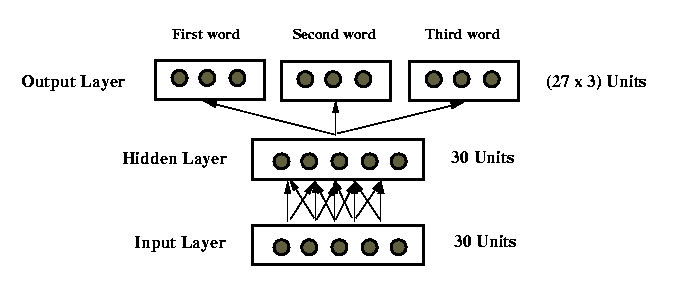
Trained parallel decoding network with 50 encoded TRAINING
sentences for ~ 7200 trials
Tested using other 50 encoded TRAINING sentences
Task: Given a distributed representation as input,
produce all words simultaneously on output units (for 2-word sentences,
third-word units have no activation)
Performance: 81% correct (i.e., no word errors)
Errors usually involved incorrect words of the same grammatical
type (noun/noun or verb/verb)
Components of distributed representations can be accessed
directly
Syntactic Transformations
Can operations be performed "holistically" on distributed
representations?
Task: NOUN1 chase NOUN2 ==> NOUN2
flee NOUN1
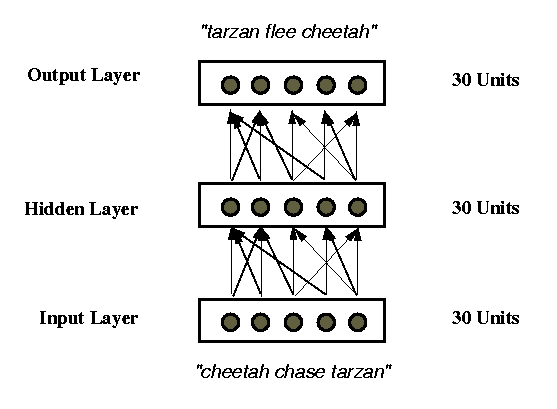
New RAAM training corpus: 20 chase/flee sentence pairs,
110 other sentences
Trained RAAM as before for ~ 3700 trials
4 novel chase/flee sentence pairs encoded using
the trained RAAM
24 chase/flee pairs total (20 used for training
RAAM, 4 novel)
Transformation network trained using 16 chase/flee
pairs (~ 75 trials)
Transformation network tested on 8 remaining chase/flee
pairs (4 trained, 4 novel)
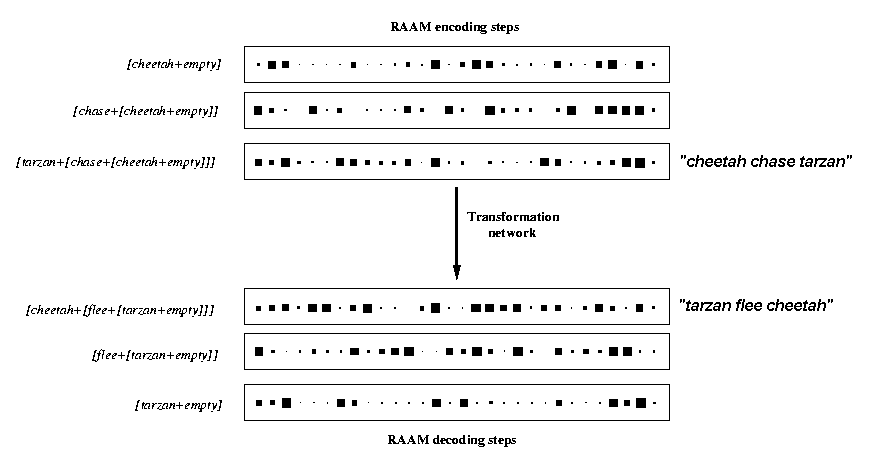
Performance:
-
100% correct on trained sentences (4/4)
-
75% correct on novel sentences (3/4)
-
Error: junglebeast chase chimp ==>
chimp flee cheetah