(Written by Xandra Long)
Intro
This summer as a part of Merideth Frey’s research team, I approached computer science projects, both furthering some of Aaron Connover’s work as well as creating my own. At the beginning of the program I collected data from our TeachSpin NMR and by the end wrote an optimization genetic algorithm (GA) for our MANDHALA’s inner magnets.
TeachSpin NMR Data
I started off this summer gathering NMR data, using the TeachSpin, from samples of various materials we had in the research lab. After altering a few existing programs, one for both T1 and T2 processes as well as putting together one for Fast Fourier Transform, I was able to upload the CSV files and end up with good data analysis and graphs. These CSV files and programs are available on my google drive shared repository.

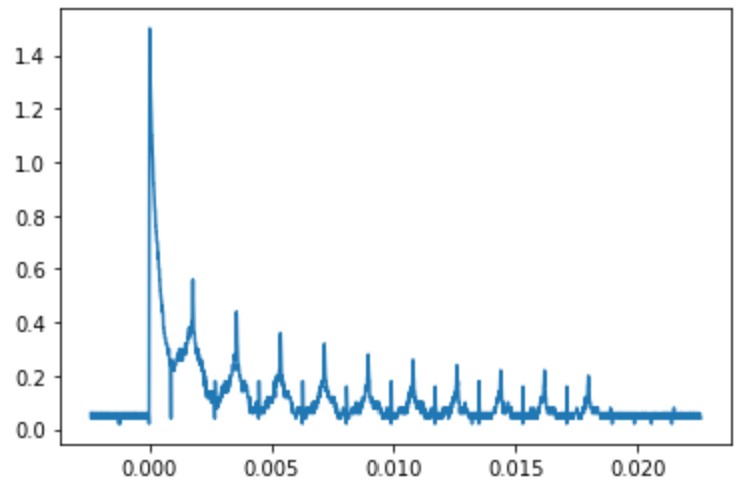
The graph below visualizes the echoes from a sample of Neoprene using our T2 Data Analysis program.
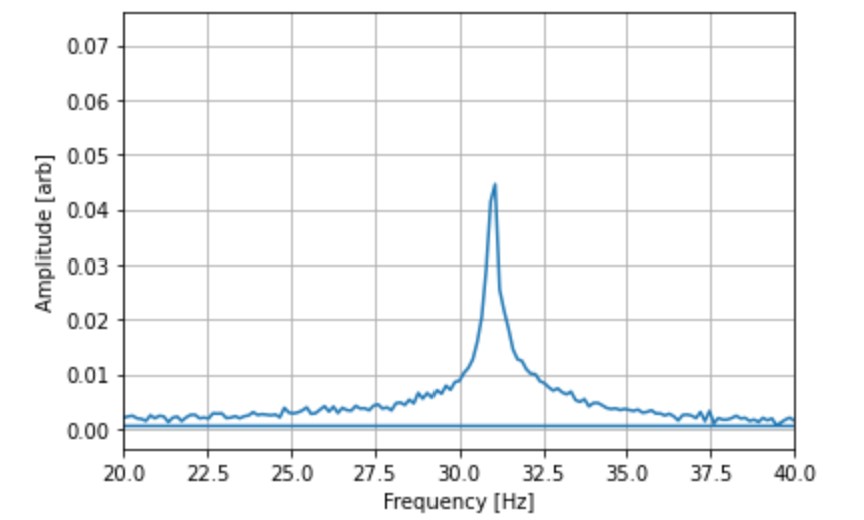
Below is a zoomed in Fourier spectrum of heavy mineral oil using the FFT (Fast Fourier Transform) program.
FEMM
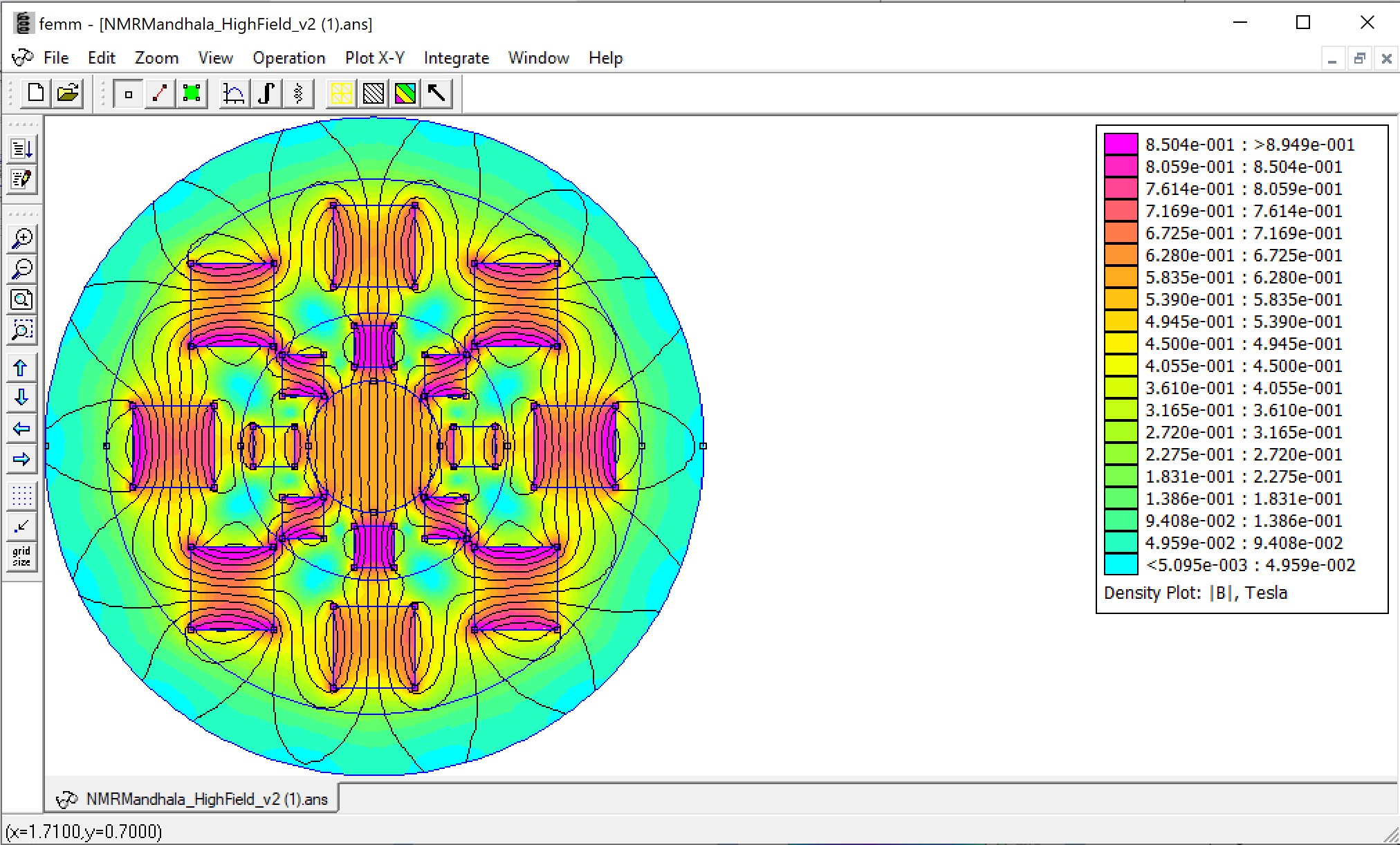
After working on building a baseline for our NMR data, I went on to test out the open source software FEMM (Finite Element Method Magnetics) which consists of multiple programs designed to solve electromagnetics problems. I mainly used this to simulate the homogeneity and collect data, though it wasn’t the most accurate considering FEMM has perfect infinite magnets and ours are finite and not exactly the same.
Optimization Problem
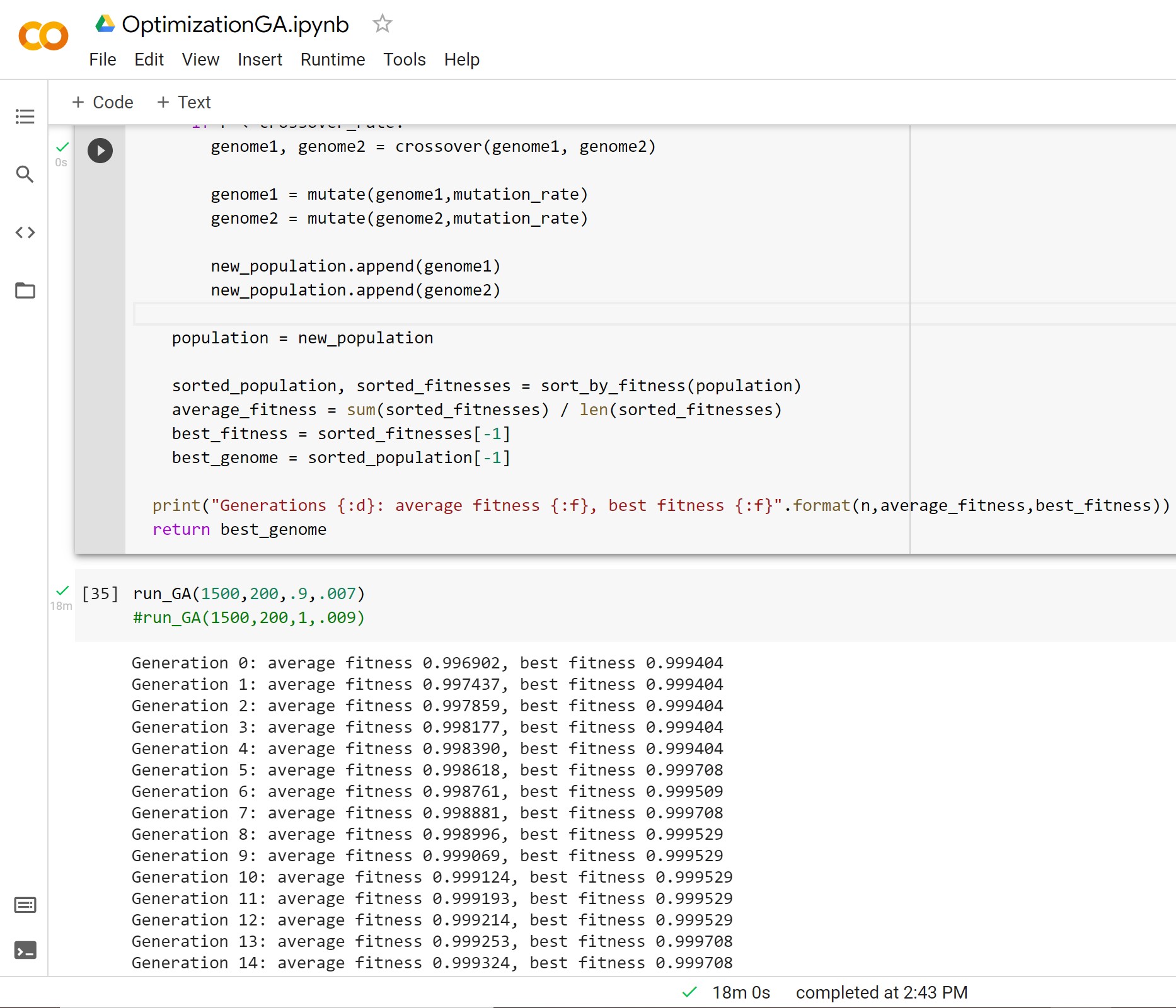
The main project I worked on this summer was furthering Aaron Connover’s work of figuring out the best optimized permutation of magnets. As we neared closer to the end of summer, we purchased a new set of 16 inner magnets which posed a challenge with our original program. The EvenMoreOptimized program efficiently runs through every single permutation of magnets(with 8 this is runs about 3 minutes and with 16, it would run for days). Due to this, it ended up being the perfect time to implement a genetic algorithm(GA). The GA would instead populate several random permutations and rank/select the best ones, mutate and switch them around to make better ones, and eventually give us the best optimization from that batch. After making sure that the permuation was in fact good, we ended up putting the magnets into the inner MANDHALA and measured the homogeneity.
Here’s the GA running. It shows the generation it’s on, the average minimum value, and the best minimum value – best permuation.
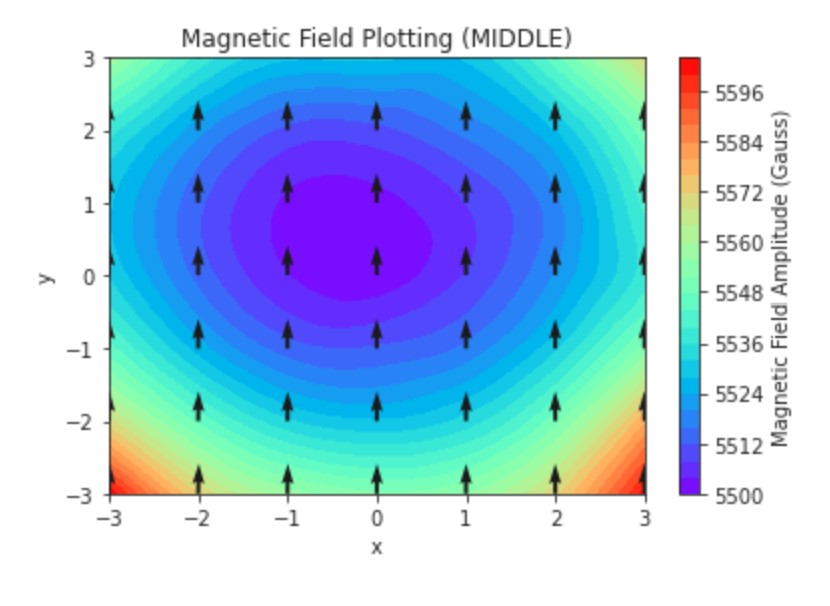
This is our magnetic field plotting program. It’s giving us a visualization of the homogeneity around the center of the MANDHALAs.
Possible Future Steps
- For our GA, there were some issues regarding the steps for crossover and mutation since each of our magnets is only usable once (for each placement in the permutation). The crossover program picks a random point along the permuation of two genomes and flips the numbers. Our mutation program chooses a random number in a permutation and inserts another number. Both of these helper functions cause the permuation to sometimes have two of multiple numbers. I have coded these to cancel the crossover or mutation if the functions detect that a repeat number has occurred, but looking into possible other helper functions for the GA would be great.
- At the moment we use the GA and the EvenMoreOptimized programs one after the other. It would likely be easier if these two programs were combined into one.