Write a program called maxquake() that prints out the single largest earthquake in earthquakes.csv, in the format shown above. Hint: use four variables called magList, locationList, timeList, and dateList, all initialized to empty lists []. As you loop through the data for each earthquake, add the earthquake's information to each of the lists "in parallel". You can then use Python's max(list) function to find the largest magnitude in magList, and from there retrieve the information from the other lists at the corresponding list positions. Don't forget to convert the earthquake magnitudes from type string to number before storing them in magList, so that the max function will give the correct result!
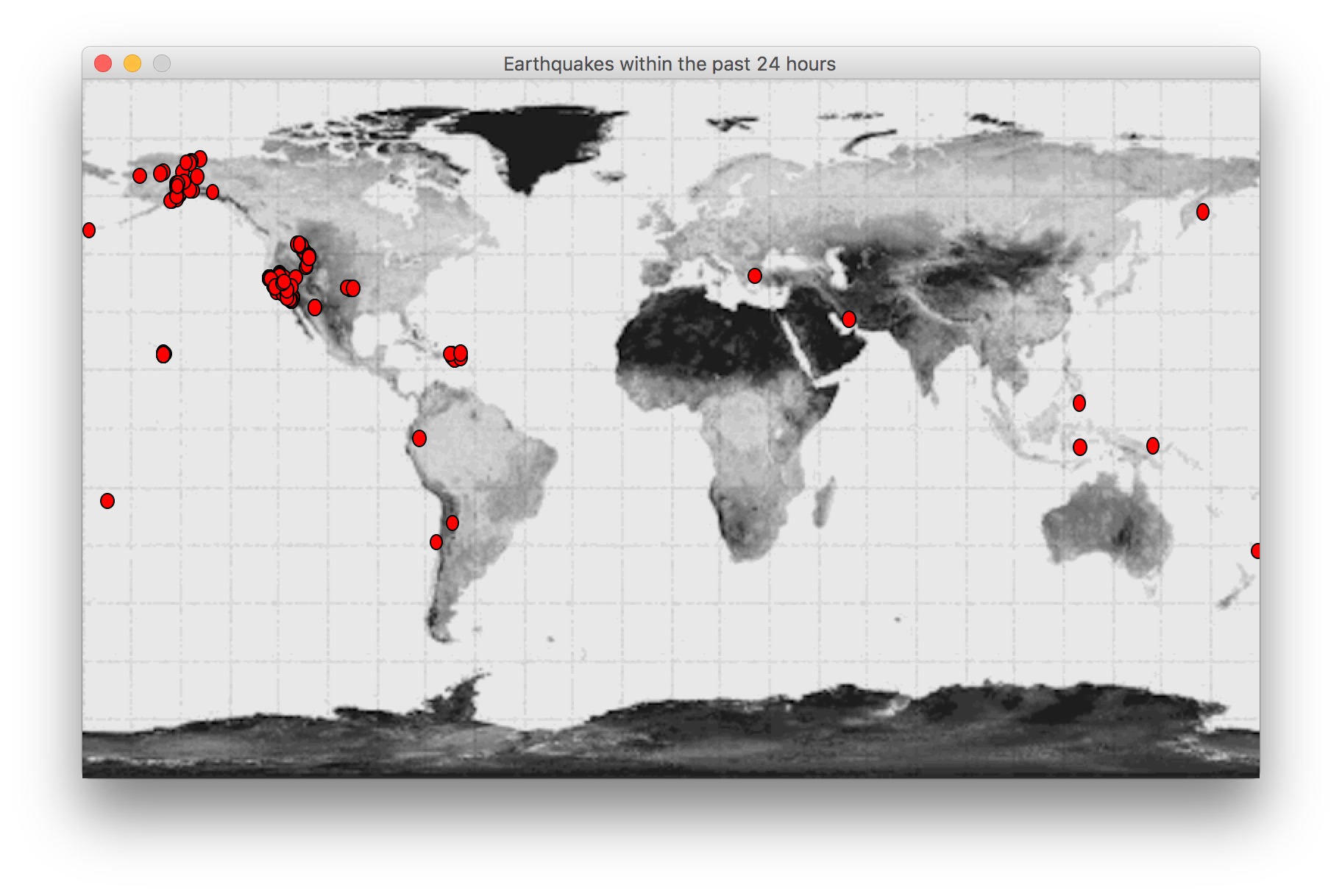
Write a program called plotquakes() that graphically plots the locations of all earthquakes in earthquakes.csv on an 800 × 475 pixel map of the world, available as the GIF image file: worldmap.gif. Create an 800 × 475 graphics window and use setCoords to set the x-coordinates of the window to the range -180 to +180 (longitude) and the y-coordinates to the range -90 to +90 (latitude). Then create an Image object from the worldmap.gif file and draw it centered in the window at (0, 0). The latitude and longitude values for each earthquake are given in fields 1 and 2, respectively. Important note: the latitude value corresponds to the y-coordinate in the graphics window, while the longitude value corresponds to the x-coordinate. Draw a small colored circle for each earthquake. If you prefer, you can choose the color (or the size) of each circle based on the magnitude of the earthquake, but this is not required. Your program's output might look something like this:
{kind=link}
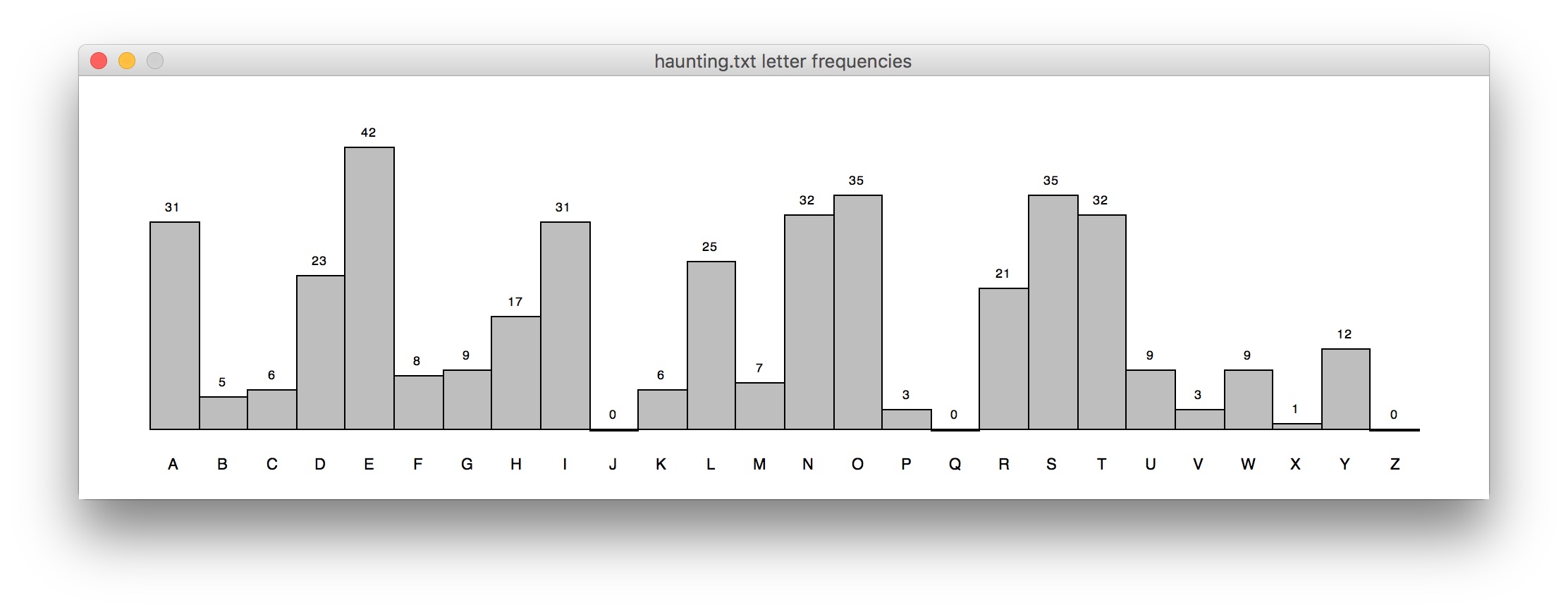
Write a program called letterhist() that asks the user for the name of a text file and then counts the number of occurrences of each letter of the alphabet in the file (ignoring upper/lower case). The program should display the results graphically as a frequency histogram showing the total number of A's, B's, C's, etc. The letter corresponding to a bar should appear at the bottom, and the actual letter count should appear just above the top of the bar (use a smaller font size for this). You should also include some blank space around the border of the histogram to improve readability. For example, a histogram created from the file haunting.txt is shown below:
Once your program works for haunting.txt, try it out on Alice's Adventures in Wonderland (alice.txt), Huckleberry Finn (huckfinn.txt), and Moby Dick (moby.txt). Make sure that it draws the histograms for these larger files correctly. If it doesn't, that means that you've built some implicit assumptions about the expected size of the input into your graphics code, so you'll need to go back and make the code more general.
How much do the overall shapes of the histograms vary for these three files? How well do they match the distribution pattern for haunting.txt? Although these texts are by different authors, they're all in English, and English has a characteristic average distribution of letter frequencies. The larger your sample size, the more your histogram will approach the average distribution for English. We can use this idea to easily break simple encryption schemes that are based on shifting all letters by the same amount in the alphabet in a circular fashion (like the substEncrypt program we wrote in class). For example, by comparing the histograms for the encrypted file mystery.txt and Moby Dick, can you figure out how to decode the mystery file? If so, do it!