Backpropagation
Variations
-
Momentum
-
Adaptive learning rate and momentum
-
Different learning rates for each weight
-
Cross-entropy error function
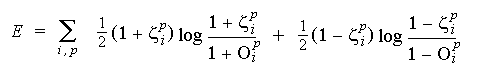
-
E > 0 except when all output values = target values (in which case
E
= 0)
-
E diverges if output of one unit saturates at the wrong extreme,
unlike previous error function
-
Has been shown to solve some problems that can't be solved with quadratic
error function
-
Eliminates derivative of activation function in error term for output units:
for tanh activation function, delta = (target-
output)
-
Pruning and weight decay
-
make each connection decay over time unless reinforced
-
wijnew = (1 - epsilon)wijold
-
or, equivalently, add a penalty term to the cost function
Training Issues
-
Overfitting: network may succeed on training set but fail to generalize
-
Training, test, and validation datasets
-
Slides from Tom Mitchell's book Machine Learning
Some Applications
-
Data compression, dimensionality-reduction
-
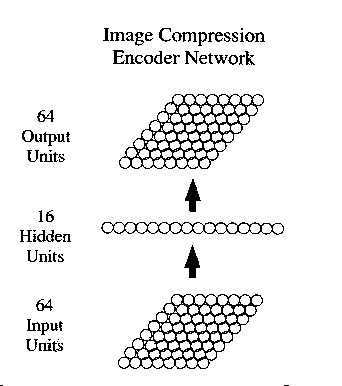
encoder networks use auto-association to compress N-dimensional patterns
to M dimensions
-
localist representation often used
-
encoders can learn a binary hidden-layer coding (assuming M > log2
N)
-
M < log2 N is sometimes possible
with continuous-valued hidden units
-
can be used for image compression (Cottrell, Munro, and Zipser)
-
took input from 8x8-pixel regions of an image
-
64 input units, 8-bit precision
-
16 hidden units
-
trained on random patches of an image for ~150,000 steps
-
tested on entire image patch by patch
-
near state of the art results (image1 image2)
-
nonlinearity in the hidden units theoretically irrelevant
-
network projects input onto M-dimensional subspace spanned by first M principal
components of input space
-
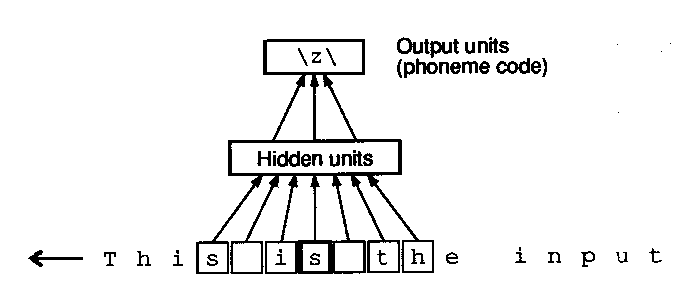
NETtalk (Sejnowski and Rosenberg)
-
network learned to pronounce English text (mapped text to phonemes)
-
network input: moving window of 7 characters
-
network output: phoneme code for center character in input window
-
output fed to a phoneme-to-speech converter
-
each input character represented by a group of 29 units (localist representation)
-
203 total input units
-
80 hidden units
-
26 output units for phonemes
-
trained on 1024 words using a side-by-side English/phoneme source
-
intelligible speech after 10 training epochs; 95% accuracy on training
corpus after 50 epochs
-
some hidden units developed meaningful responses (e.g., vowels vs. consonants)
-
generalization: 78% accuracy on continuation of training text
-
damaging network produced graceful degradation, with rapid recovery on
retraining
-
DECtalk performs better, but uses hand-coded linguistic rules developed
over a decade
-
ALVINN (Pomerleau)
-
network controlled steering of a car on a winding road
-
network inputs: 30 x 32 pixel image from a video camera, 8 x 32 gray scale
image from a range finder
-
29 hidden units
-
45 output units arranged in a line corresponding to steering angle
-
achieved speeds of up to 70 mph for 90 minutes on highways outside of Pittsburgh
-
NavLab photos
-
NavLab home page
-
Protein secondary structure (Qian and Sejnowski)
-
network learned to predict protein secondary structure from amino acid
sequence
-
network input: moving window of 13 amino acids
-
network output: prediction of alpha-helix, beta-sheet, or
other
-
similar to NETtalk
-
achieved 62% accuracy on unseen sequences (best alternative approach yields
53% accuracy)
-
may be close to best possible accuracy achievable from a local window
-
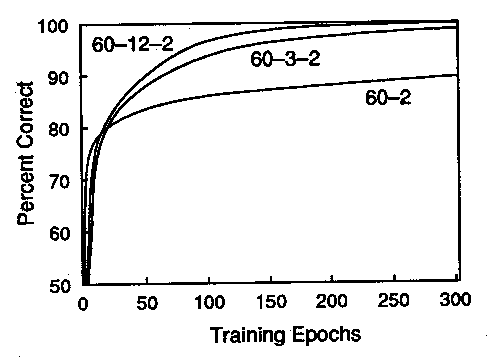
Sonar target recognition (Gorman and Sejnowski)
-
trained 2-layer backprop network to distinguish between reflected sonar
signals of rocks and metal cylinders at bottom of Chesapeake Bay
-
60 input units, 2 output units
-
input patterns based on Fourier transform of raw time signal
-
tried varying numbers of hidden units (0, 3, 12, 24)
-
best performance with 12 hidden units (close
to 100% accuracy)
-
85-90% classification accuracy for signals not in training set
-
Backgammon (Tesauro)
-
Neurogammon program trained to score backgammon moves
-
network input: triples{board position, dice values, possible move} plus
some precomputed features (e.g., degree of trapping)
-
network output: single score value from -100 (bad) to +100 (good)
-
459 input units
-
two hidden layers of 24 units each
-
noise added to training data in the form of randomly chosen scores
-
noise actually improves the performance to some extent
-
exhibited a great deal of "common sense" (almost always chose best move
in intuitively clear situations)
-
won the gold medal at the computer olympiad in London in 1989
-
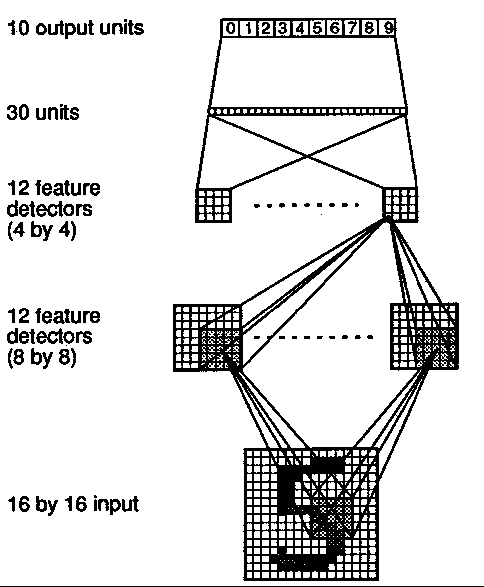
Hand-written ZIP code recognition
(LeCun group at AT&T Bell Labs)
-
~10,000 digits from the U.S. mail were used
to train and test system
-
ZIP codes on envelopes were initially located and segmented by a separate
system (difficult task in itself)
-
network input: 16 x 16 pixel array, scaled to standard size
-
three hidden layers, 10 output units (for digits 0-9)
-
first two hidden layers organized into groups of feature detectors
-
weight sharing used to constrain number of free parameters
-
1256 units + 30060 links + 1000 biases, but only 9760 free parameters
-
used an accelerated version of backprop (pseudo-Newton rule)
-
trained on 7300 digits, tested on 2000
-
error rate of ~1% on training set, ~5% on test set
-
if marginal cases were rejected (two or more outputs approximately the
same), error reduced to ~1% with 12% rejected
-
used "optimal brain damage" technique to prune unnecessary weights
-
after removing weights and retraining, only ~1/4 as many free parameters
as before, but better performance
-
99% classification accuracy with 9% rejection rate
-
achieved state of the art in digit recognition
-
much problem-specific knowledge was designed into the network architecture
-
preprocessing of input data was crucial to success
-
Electronic
noses
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}