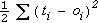 , where
ti is the
target value for output unit i and oi is the actual
output value for that unit.
, where
ti is the
target value for output unit i and oi is the actual
output value for that unit.
Documentation for the original C version of this assignment is also available (in PostScript format).
Although you will be able to use most of the code without modification, you will need to know a little bit about the routines and data structures, so that you can easily implement new output encodings for your networks. The following sections describe each of the packages in a little more detail, but you should look at BPNN.java, facetrain.java, and PGMimage.java to see how the pieces all fit together.
In fact, it is probably a good idea to look over facetrain.java first, to see how the training process works. You will notice that the set_target method in BPNN.java is called to set up the target vector for training. You will also notice the routines show_performance_on_dataset, show_misclassified_images, and correct_response, which evaluate performance and compute error statistics.
You will almost certainly not need to use all of the information in the following sections, so don't feel like you need to know everything the packages do. You should view these sections as reference guides for the packages, should you need information on data structures and routines.
Another fun thing to do is to use the output2pgm and hidden2pgm utilities to view the weights on connections in graphical form. See the comments in the source code for information on how to use these programs.
Finally, the point of this assignment is for you to obtain first-hand experience in working with neural networks; it is not intended as an exercise in Java or C hacking. An effort has been made to keep things as simple as possible. If you need clarification on how the code works, please don't hesitate to ask.
PGMimage.java - Supports reading and writing of PGM image files and pixel access/assignment. You will not need to modify any of the code in this class to complete the assignment.
BPNN.java - The neural network class. Supports three-layer fully-connected feedforward networks, using the backpropagation algorithm for weight tuning. Provides high-level routines for creating, training, and using networks. The methods set_target and correct_response are also in this class; you will need to modify these for your face and pose recognizers.
facetrain.java - The top-level program which uses all of the classes above to implement a "glickman" recognizer. You will need to modify this code to change network sizes and learning parameters, both of which are trivial changes.
hidden2pgm.java, output2pgm.java - Utilities for visualizing network weights. It's not necessary to modify anything here, although it may be interesting to explore some of the many possible alternate visualization schemes.
<epoch> <train%> <trainerr> <t1%> <t1err> <t2%> <t2err>
These values have the following meanings:
<epoch> is the number of the epoch just completed; a value of 0 means that no training has yet been performed.
<train%> is the percentage of examples in the training set that were correctly classified.
<trainerr> is the average, over all training examples,
of the error function , where
ti is the
target value for output unit i and oi is the actual
output value for that unit.
<t1%> is the percentage of examples in test set 1 that were correctly classified.
<t1err> is the average, over all examples in test set 1, of the error function described above.
<t2%> is the percentage of examples in test set 2 that were correctly classified.
<t2err> is the average, over all examples in test
set 2, of the error function described above.